1. El comienzo del aprendizaje profundo: principios fundamentales y el contexto de la evolución tecnológica
El inicio de la exploración del ADN del aprendizaje profundo
“La verdadera innovación en la tecnología nace de los fracasos pasados” - Geoffrey Hinton, discurso de aceptación del Premio Turing 2018
1.1 El propósito de este libro
El aprendizaje profundo es un campo dentro del aprendizaje automático que ha experimentado un desarrollo rápido y ha mostrado resultados sorprendentes recientemente. Han surgido modelos de lenguaje grandes (LLMs) como GPT-4 y Gemini, y coexisten las expectativas y preocupaciones sobre la inteligencia artificial general (AGI). Con el rápido avance de los artículos de investigación y tecnologías, incluso los expertos encuentran difícil mantenerse al día.
Esta situación es similar a finales de la década de 1980, cuando las PC y los lenguajes de programación se popularizaron. En aquel entonces, surgió una gran cantidad de tecnologías, pero solo unas pocas tecnologías nucleares terminaron siendo la base de la computación moderna. De manera similar, entre las diversas arquitecturas de aprendizaje profundo actuales, como redes neuronales, CNNs, RNNs, transformers, difusión y multimodalidad, solo un pequeño número que comparte ADN clave seguirá siendo fundamental para el desarrollo continuo de la IA.
Este libro comenzó desde esta perspectiva. En lugar de simplemente explicar métodos de API o teoría básica y ejemplos, se centra en la anatomía del ADN tecnológico. Desde el modelo de neurona McCulloch-Pitts de 1943 hasta las arquitecturas multimodales más recientes de 2025, como si fuera un proceso evolutivo, se enfoca en el fondo que llevó a la aparición de cada tecnología, los problemas fundamentales que buscaba resolver y sus vínculos con tecnologías anteriores. Es decir, traza un árbolo genealógico de las tecnologías de aprendizaje profundo. La sección 1.2 resume brevemente este contenido.
Para lograrlo, este libro tiene las siguientes características:
Explicaciones desde la perspectiva del ADN: No solo enumera tecnologías, sino que explica por qué surgieron, qué problemas resolvían y cómo se relacionaban con tecnologías anteriores, es decir, el filiación (phylogeny) de la tecnología.
Explicaciones concisas pero profundas: Ayuda a comprender claramente los conceptos y principios clave, omitiendo audazmente detalles innecesarios.
Refleja las tendencias tecnológicas más recientes: Incluye las tecnologías más actuales hasta 2025 (por ejemplo, Redes Retentivas, Mezcla de Expertos, Modelos Multimodales) para abordar la vanguardia del desarrollo del aprendizaje profundo.
Puente entre la práctica y la investigación: Presenta ejemplos de código prácticos y una intuición matemática equilibrada para conectar la teoría con la práctica.
Ejemplos avanzados: Más allá de simplemente proporcionar códigos que funcionen, ofrece ejemplos lo suficientemente desarrollados como para ser aplicables directamente en investigación o desarrollo.
A través de esto, el objetivo es ayudar a los profesionales y investigadores a aumentar su competencia. Además, se pretende abordar las consideraciones éticas y sociales de la tecnología AI y reflexionar sobre la democratización tecnológica.
1.2 Historia del Deep Learning
Desafío: ¿Cómo hacer que las máquinas piensen y aprendan como los humanos?
Angustia de los investigadores: Imitar el complejo funcionamiento del cerebro humano era una tarea extremadamente difícil. Los investigadores iniciales dependían de sistemas basados en reglas simples o bases de datos de conocimiento limitadas, pero esto tenía limitaciones para manejar la diversidad y complejidad del mundo real. Para crear un sistema verdaderamente inteligente, se necesitaba la capacidad de aprender por sí mismo a partir de los datos, reconocer patrones complejos y comprender conceptos abstractos. Implementar esto era el desafío central.
La historia del deep learning comenzó en 1943 cuando Warren McCulloch y Walter Pitts presentaron un modelo matemático llamado McCulloch-Pitts Neuron, que explicaba cómo funcionan las neuronas, definiendo así los componentes básicos de una red neuronal. En 1949, Donald Hebb propuso la regla del Aprendizaje Hebbiano, explicando el ajuste de los pesos sinápticos, es decir, el principio básico del aprendizaje. En 1958, el perceptrón de Frank Rosenblatt fue la primera red neuronal práctica, pero se enfrentó a limitaciones en la clasificación no lineal, como el problema XOR.
La década de 1980 marcó un punto de inflexión crucial. En 1980, Kunihiko Fukushima propuso el Neocognitron (base del principio de convolución), que más tarde se convertiría en la idea central de las CNN. El desarrollo más importante fue el algoritmo de propagación hacia atrás (backpropagation) por parte del equipo de Geoffrey Hinton en 1986. Este algoritmo permitió un aprendizaje efectivo en redes neuronales multicapa y se estableció como el núcleo del aprendizaje de redes neuronales. En 2006, Hinton introdujo el término “deep learning”, marcando un nuevo comienzo.
Desde entonces, el deep learning ha crecido rápidamente gracias al desarrollo de grandes conjuntos de datos y poder computacional. En 2012, AlexNet ganó la competencia ImageNet con un rendimiento sobresaliente, demostrando la practicidad del deep learning. Posteriormente, surgieron arquitecturas innovadoras que utilizaban Redes Recurrentes, como el LSTM (1997) y el Mecanismo de Atención (2014). En particular, en 2017, Google presentó el Transformer, que cambió completamente el paradigma del procesamiento de lenguaje natural. A través del Self-Attention, conecta directamente cada parte de la secuencia de entrada con otras partes, resolviendo problemas de dependencia a larga distancia.
Basado en el Transformer, surgieron BERT y las series GPT, lo que llevó a un desarrollo significativo en el rendimiento de los modelos de lenguaje. Word2Vec (2013) abrió nuevas perspectivas en el embedding de palabras. En el campo de los Modelos Generativos, desde el LSTM (1997) hasta FlashAttention (después de 2023), se ha logrado la generación de imágenes de alta calidad con Vision Transformer (ViT) (2021), lo que aceleró el desarrollo del Aprendizaje Multimodal.
Los modelos de lenguaje grandes recientes como GPT-4 y Gemini han aumentado las expectativas sobre la posibilidad de lograr una IA general. Estos utilizan arquitecturas avanzadas como Redes Retentivas (2023), técnicas de eficiencia como FlashAttention y métodos como Mixture of Experts (MoE) (2024) para volverse más sofisticados. Además, evolucionan hacia modelos Multimodales que integran diferentes tipos de datos, como texto, imágenes y audio (Gemini Ultra 2.0 en 2024 y Gemini 2.0 en 2025), mostrando habilidades cognitivas de alto nivel más allá del simple Q&A, incluyendo inferencia, creación y resolución de problemas.
El desarrollo del deep learning se basa en los siguientes elementos clave. 1. Aumento de la disponibilidad de datos a gran escala 2. Desarrollo de recursos de computación de alto rendimiento, como GPUs 3. Backpropagation, Attention, Transformer y desarrollo de algoritmos de aprendizaje eficientes, así como de Core Architecture, Generative Models
A pesar de estos avances, aún quedan desafíos por resolver. La explicabilidad de los modelos (Interpretability), la eficiencia en el uso de datos, el consumo de energía y los problemas de desarrollo de Efficiency & Advanced Concepts son tareas importantes.
A continuación se presenta una visualización del árbol genealógico técnico. |
Después de que Warren McCulloch y Walter Pitts propusieran el modelo de red neuronal artificial (McCulloch-Pitts Neuron) en 1943, en 1949, Donald O. Hebb, un psicólogo canadiense, presentó los principios fundamentales del aprendizaje de redes neuronales en su libro “The Organization of Behavior”. Este principio se conoce como regla de Hebb (Hebb’s Rule) o aprendizaje hebbiano (Hebbian Learning) y ha tenido un gran impacto en la investigación de redes neuronales artificiales, incluido el deep learning.
1.3.1 Regla del Aprendizaje Hebbiano
La idea central del aprendizaje hebbiano es muy simple: si dos neuronas se activan simultáneamente o repetidamente, la fuerza de conexión entre ellas aumenta. Por el contrario, si las dos neuronas se activan en diferentes momentos o una neurona se activa y la otra no, la fuerza de conexión disminuye o desaparece.
Esto se puede expresar matemáticamente de la siguiente manera:
\[
\Delta w_{ij} = \eta \cdot x_i \cdot y_j
\]
Donde,
\(\Delta w_{ij}\) es el cambio en la fuerza de conexión (peso) entre la neurona \(i\) y la neurona \(j\).
\(\eta\) es la tasa de aprendizaje (learning rate), una constante que ajusta la magnitud del cambio en la fuerza de conexión.
\(x_i\) es el valor de activación (entrada) de la neurona \(i\).
\(y_j\) es el valor de activación (salida) de la neurona \(j\).
Esta ecuación muestra que cuando ambas neuronas \(i\) y \(j\) se activan (\(x_i\) y \(y_j\) son ambos positivos), la fuerza de conexión aumenta (\(\Delta w_{ij}\) es positivo). Por el contrario, si solo una de ellas se activa o ninguna de las dos se activa, la fuerza de conexión disminuye o no cambia. El aprendizaje hebbiano es una de las primeras formas de aprendizaje no supervisado (unsupervised learning). Es decir, sin que se proporcionen respuestas correctas (labels), la red neuronal ajusta por sí misma la fuerza de conexión mientras aprende a partir de los patrones en los datos de entrada.
1.3.2 Relación con la Plasticidad Cerebral
El aprendizaje hebbiano va más allá de ser una simple regla matemática y proporciona importantes insights sobre el funcionamiento del cerebro real. El cerebro cambia constantemente a través de la experiencia y el aprendizaje, y estos cambios se conocen como plasticidad cerebral (brain plasticity) o plasticidad neural (neural plasticity). El aprendizaje hebbiano desempeña un papel clave en la explicación de una forma de plasticidad neural llamada plasticidad sináptica (synaptic plasticity). Los sinapsis son las conexiones entre las neuronas y determinan la eficiencia del intercambio de información. El aprendizaje hebbiano ilustra claramente el principio fundamental de la plasticidad sináptica, es decir, “las neuronas que se activan juntas, se conectan juntas”. La potenciación a largo plazo (Long-Term Potentiation, LTP) y la depresión a largo plazo (Long-Term Depression, LTD) son ejemplos representativos de plasticidad sináptica. LTP es un fenómeno en el que las conexiones sinápticas se fortalecen según la regla del aprendizaje hebbiano, mientras que LTD es el fenómeno contrario. LTP y LTD desempeñan roles importantes en el aprendizaje, la memoria y el desarrollo cerebral.
1.4 Redes Neuronales (NN, Neural Network)
Las redes neuronales son aproximadores de funciones que reciben entradas y generan valores lo más cercanos posible a la salida deseada. Esto se expresa matemáticamente como \(f_\theta\), donde \(f\) es la función y \(\theta\) representa los parámetros compuestos por pesos (weight) y sesgos (bias). El núcleo de las redes neuronales radica en su capacidad para aprender automáticamente estos parámetros a partir de los datos.
La primera red neuronal, propuesta por Warren McCullough y Walter Pitts en 1944, se inspiró en las neuronas biológicas, aunque las redes neuronales modernas son modelos puramente matemáticos. En realidad, las redes neuronales son poderosas herramientas matemáticas capaces de aproximar funciones continuas, lo cual ha sido demostrado por el teorema de aproximación universal (Universal Approximation Theorem).
1.4.1 Estructura Básica de las Redes Neuronales
Las redes neuronales tienen una estructura jerárquica compuesta por capas de entrada, capas ocultas y capas de salida. Cada capa está formada por nodos (neuronas) que se conectan entre sí para transmitir información. Básicamente, las redes neuronales están constituidas por una combinación de transformaciones lineales y funciones de activación no lineales.
Matemáticamente, cada capa de una red neuronal realiza la siguiente transformación lineal:
\[ y = Wx + b \]
donde:
\(x\) es el vector de entrada
\(W\) es la matriz de pesos
\(b\) es el vector de sesgos
\(y\) es el vector de salida
A pesar de que esta estructura puede parecer simple, una red neuronal con suficientes neuronas y capas puede aproximar cualquier función continua con la precisión deseada. Este es el motivo por el cual las redes neuronales pueden aprender patrones complejos y resolver diversos problemas.
Haga clic para ver el contenido (deep dive: teorema de aproximación universal)
Teorema de Aproximación Universal
Desafío: ¿Cómo se puede demostrar que una red neuronal puede aproximar cualquier función compleja?
Preocupaciones del investigador: Incluso con muchas capas y neuronas, no era evidente si una red neuronal realmente podía representar cualquier función continua. Había preocupación de que solo combinando transformaciones lineales simples podría ser difícil expresar la complejidad no lineal. Depender únicamente de resultados empíricos sin garantías teóricas fue un gran obstáculo para el desarrollo de la investigación en redes neuronales.
Teorema de Aproximación Universal (Universal Approximation Theorem)
El Teorema de Aproximación Universal es una teoría fundamental que respalda el poder de representación de las redes neuronales. Este teorema demuestra que, una red neuronal de una sola capa con un número suficientemente grande de neuronas ocultas, puede aproximar cualquier función continua con la precisión deseada.
Idea clave:
Funciones de activación no lineales: Las funciones de activación no lineales como ReLU, sigmoid y tanh son componentes esenciales que permiten a las redes neuronales expresar no linealidad. Sin estas funciones de activación, incluso con muchas capas, solo serían una combinación de transformaciones lineales.
Capa oculta suficientemente grande: Si el número de neuronas en la capa oculta es suficiente, la red neuronal adquiere la “flexibilidad” para representar cualquier función compleja. Es similar a poder crear cualquier imagen de mosaico con un número suficiente de piezas.
Expresión matemática:
Teorema (Teorema de Aproximación Universal):
Sea \(f : K \rightarrow \mathbb{R}\) una función continua definida en un conjunto compacto \(K \subset \mathbb{R}^d\). Dado cualquier límite de error \(\epsilon > 0\), existe una red neuronal de una sola capa\(F(x)\) que satisface la siguiente condición.
\(|f(x) - F(x)| < \epsilon\), para todo \(x \in K\).
Aquí, \(F(x)\) tiene la siguiente forma.
\(F(x) = \sum_{i=1}^{N} w_i \cdot \sigma(v_i^T x + b_i)\)
Explicación detallada:
\(f : K \rightarrow \mathbb{R}\):
\(f\) es la función objetivo que se desea aproximar.
\(K\) es el dominio de la función, un conjunto compacto en \(\mathbb{R}^d\) (espacio real d-dimensional). Un conjunto compacto intuitivamente significa “con fronteras y cerrado”. Por ejemplo, en una dimensión, un intervalo cerrado [a, b] es un conjunto compacto. Esta condición no es restrictiva en la práctica, ya que la mayoría de los datos de entrada reales tienen un rango limitado.
\(\mathbb{R}\) es el conjunto de números reales. Es decir, la función \(f\) asigna cada punto (\(x\)) en \(K\) a un valor real (\(f(x)\)). (Para funciones multivariables y múltiples salidas, se explica adicionalmente a continuación.)
\(\epsilon > 0\): Un número positivo arbitrario que representa la precisión de la aproximación. Cuanto más pequeño sea \(\epsilon\), más precisa será la aproximación.
\(|f(x) - F(x)| < \epsilon\): Significa que para todo \(x \in K\), la diferencia entre el valor real de la función \(f(x)\) y la salida de la red neuronal \(F(x)\) es menor que \(\epsilon\). Es decir, la red neuronal puede aproximar la función \(f\) dentro del rango de error \(\epsilon\).
\(F(x) = \sum_{i=1}^{N} w_i \cdot \sigma(v_i^T x + b_i)\): Representa la estructura de una red neuronal de una sola capa.
\(N\): es el número de neuronas (unidades) en la capa oculta. El teorema de aproximación universal garantiza la existencia de un \(N\)suficientemente grande, pero no especifica cuánto debe ser exactamente.
\(w_i \in \mathbb{R}\): es el peso de salida (output weight) entre la neurona \(i\)-ésima de la capa oculta y la neurona de la capa de salida. Es un valor escalar.
\(\sigma\): es una función de activación no lineal. Se pueden usar diversas funciones como ReLU, sigmoid, tanh, leaky ReLU, etc. Para que el teorema de aproximación universal se cumpla, \(\sigma\) debe ser no polinomial (non-polynomial) y debe ser acotada (bounded) o continua por tramos (piecewise continuous).
\(v_i \in \mathbb{R}^d\): es el vector de pesos de entrada (input weight vector) para la neurona \(i\)-ésima de la capa oculta. Tiene la misma dimensión que la entrada \(x\).
\(v_i^T x\): es el producto interno (inner product, dot product) entre los vectores \(v_i\) y \(x\).
\(b_i \in \mathbb{R}\): es el sesgo (bias) de la neurona \(i\)-ésima de la capa oculta. Es un valor escalar.
Funciones multivariables: El teorema de aproximación universal también se aplica cuando la entrada \(x\) es un vector (\(x \in \mathbb{R}^d\), \(d > 1\)). La operación \(v_i^T x\) (producto interno) maneja naturalmente las entradas multivariables.
Múltiples salidas: Cuando la función \(f\) tiene múltiples valores de salida (\(f : K \rightarrow \mathbb{R}^m\), \(m > 1\)), se pueden usar neuronas y pesos de salida separados para cada salida. Así, \(F(x)\) tendrá una salida en forma de vector y se puede asegurar que el error de aproximación para cada salida sea menor que \(\epsilon\).
Velocidad de convergencia del error (Teorema de Barron):
Según el teorema de Barron, bajo ciertas condiciones (condiciones sobre la transformada de Fourier de la función de activación y la función a aproximar), el error \(\epsilon\) tiene la siguiente relación con el número de neuronas \(N\):
\(\epsilon(N) = O(N^{-1/2})\)
Esto significa que el error disminuye a una tasa de \(N^{-1/2}\) a medida que aumenta el número de neuronas. En otras palabras, al cuadruplicar el número de neuronas, el error se reduce aproximadamente a la mitad. Esta es la velocidad general de convergencia, aunque para funciones o funciones de activación específicas, la velocidad puede ser más rápida o más lenta.
Contraejemplos y limitaciones:
Aproximación en frontera: Funciones como \(e^{-1/x^2}\) que son infinitamente diferenciables en \(x=0\), pero con cambios bruscos, pueden ser difíciles de aproximar cerca de \(x=0\) usando redes neuronales. Este problema surge porque la serie de Taylor de dichas funciones es cero, aunque la función misma no lo sea.
Complejidad exponencial de funciones discretas: El número de neuronas necesarias para aproximar una función booleana de \(n\) variables puede ser proporcional a \(2^n / n\) en el peor caso. Esto significa que el número de neuronas requeridas puede aumentar exponencialmente con el número de variables de entrada, mostrando que las redes neuronales no pueden aproximar eficientemente todas las funciones.
Resumen clave: El teorema de aproximación universal establece que una red neuronal de un solo nivel con un capa oculta suficientemente ancha puede aproximar cualquier función continua definida en un conjunto acotado y cerrado con la precisión deseada. La función de activación debe ser no polinomial. Esto implica que las redes neuronales tienen una gran capacidad representativa (representational power) y proporcionan una base teórica para el aprendizaje profundo. El teorema de Barron ofrece insights sobre la velocidad de convergencia del error.
Puntos importantes
Prueba de existencia: El teorema de aproximación universal es una prueba de existencia y no propone un algoritmo de aprendizaje. Asegura que existe tal red neuronal, pero cómo encontrarla en la práctica es otro problema. (Los algoritmos de retropropagación y descenso del gradiente son métodos para resolver este problema.)
Redes simples vs. redes profundas: En la práctica, las redes neuronales profundas suelen ser más eficientes y tener un mejor rendimiento en generalización que las redes neuronales de un solo nivel. Aunque el teorema de aproximación universal proporciona una base teórica para el aprendizaje profundo, el éxito del aprendizaje profundo es el resultado de la combinación de múltiples capas, arquitecturas especializadas y algoritmos de aprendizaje eficientes. Teóricamente, las redes neuronales de un solo nivel pueden representar todo, pero su entrenamiento en la práctica puede ser mucho más difícil.
Conocimiento de los límites: Aunque el teorema de aproximación universal es un resultado poderoso, no garantiza que todas las funciones puedan ser aproximadas eficientemente. Como se ve en contraejemplos, ciertas funciones pueden requerir una cantidad muy grande de neuronas para ser aproximadas.
Referencias:
Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals, and Systems, 2(4), 303-314. (Teorema de aproximación universal inicial para funciones de activación sigmoide)
Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2(5), 359-366. (Teorema de aproximación universal para funciones de activación más generales)
Barron, A. R. (1993). Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information Theory, 39(3), 930-945. (Teorema de Barron sobre la velocidad de convergencia del error)
Pinkus, A. (1999). Approximation theory of the MLP model in neural networks. Acta Numerica, 8, 143-195. (Revisión más profunda del teorema de aproximación universal)
Goodfellow, I., Bengio, Y., & Courville, A. (2016).Deep Learning. MIT Press. (Capítulo 6.4: Texto de aprendizaje profundo. Incluye contenido relacionado con el teorema de aproximación universal)
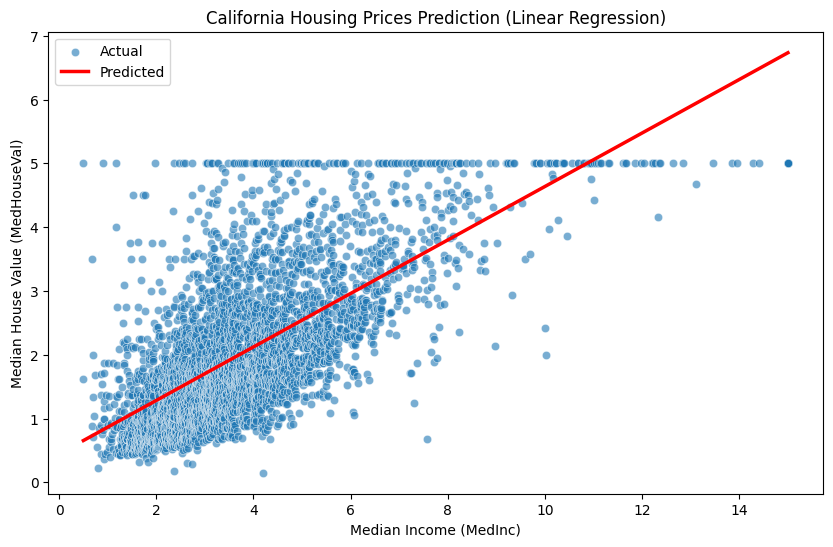
1.4.2 Predicción de precios de viviendas utilizando un aproximador lineal (linear approximator)
Para comprender los conceptos básicos de las redes neuronales, examinaremos un problema de regresión lineal simple. Aquí utilizamos el conjunto de datos de precios de viviendas en California de la biblioteca scikit-learn. Este conjunto de datos incluye varias características (features) de las viviendas y se puede usar para crear un modelo que prediga los precios de las viviendas. Como ejemplo simple, asumiremos que el precio de una vivienda depende solo de una característica: el ingreso medio (MedInc), e implementaremos un aproximador lineal.
Code
import numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.datasets import fetch_california_housingfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split# Load the California housing datasethousing = fetch_california_housing(as_frame=True)data = housing.frame# Use only Median Income (MedInc) and Median House Value (MedHouseVal)data = data[["MedInc", "MedHouseVal"]]# Display the first 5 rows of the dataprint(data.head())# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split( data[["MedInc"]], data["MedHouseVal"], test_size=0.2, random_state=42)# Create and train a linear regression modelmodel = LinearRegression()model.fit(X_train, y_train)# Make predictions on the test datay_pred = model.predict(X_test)# Prepare data for visualizationplot_data = pd.DataFrame({'MedInc': X_test['MedInc'], 'MedHouseVal': y_test, 'Predicted': y_pred})# Sort for better line plot visualization. Crucially, sort *after* prediction.plot_data = plot_data.sort_values(by='MedInc')# Visualize using Seabornplt.figure(figsize=(10, 6))sns.scatterplot(x='MedInc', y='MedHouseVal', data=plot_data, label='Actual', alpha=0.6)sns.lineplot(x='MedInc', y='Predicted', data=plot_data, color='red', label='Predicted', linewidth=2.5)plt.title('California Housing Prices Prediction (Linear Regression)')plt.xlabel('Median Income (MedInc)')plt.ylabel('Median House Value (MedHouseVal)')plt.legend()plt.show()# Print the trained weight (coefficient) and bias (intercept)print("Weight (Coefficient):", model.coef_[0])print("Bias (Intercept):", model.intercept_)
El código primero carga el conjunto de datos de precios de viviendas de California usando la función fetch_california_housing. Luego, obtiene los datos en formato de DataFrame de Pandas con as_frame=True y selecciona solo las características del precio de la vivienda (MedHouseVal) y el ingreso mediano (MedInc). Después de dividir los datos en conjuntos de entrenamiento y prueba utilizando la función train_test_split, se crea un modelo de regresión lineal con la clase LinearRegression y se entrena el modelo con los datos de entrenamiento usando el método fit. El modelo entrenado realiza predicciones en los datos de prueba mediante el método predict y visualiza los valores reales y las predicciones utilizando Seaborn. Finalmente, se imprimen los pesos y sesgos del modelo entrenado.
Así, es posible realizar ciertas predicciones con una simple transformación lineal. Las redes neuronales agregan funciones de activación no lineales y apilan múltiples capas para aproximar funciones mucho más complejas.
1.4.3 El camino a las redes neuronales: el proceso de operaciones matriciales
La etapa previa de una red neuronal es un aproximador lineal. Aquí, examinaremos en detalle cómo el ejemplo anterior llega al valor real. La forma lineal más simple para el valor real \(\boldsymbol y\) es \(\boldsymbol y = \boldsymbol x \boldsymbol W + \boldsymbol b\).
Aquí, \(\boldsymbol W\) es el peso (weight parameter), y \(\boldsymbol b\) es el sesgo (bias). Optimizar estos dos parámetros a partir de los datos es la clave del aprendizaje de la red neuronal. Como veremos en 1.4, las redes neuronales introducen no linealidad agregando funciones de activación a las transformaciones lineales y optimizando los parámetros a través del backpropagation. Aquí, solo examinaremos el proceso de cálculo simple utilizando transformaciones lineales y backpropagation.
Inicialmente, se establecen los parámetros con valores aleatorios.
La optimización de los parámetros se realiza utilizando el gradiente (gradient). El gradiente apunta en la dirección en la que el error aumenta, por lo que se resta del parámetro actual para reducir el error. Introduciendo una tasa de aprendizaje (\(\eta\)),
El sesgo también se actualiza de la misma manera. Repitiendo este cálculo de adelante (forward) y atrás (backward), los parámetros se optimizan, lo cual es el proceso de aprendizaje de una red neuronal.
1.3.4 Implementación con NumPy
Examinemos la implementación de un aproximador lineal utilizando NumPy. Primero, preparamos los datos de entrada y los valores objetivo.
Code
import numpy as np# Set input values and target valuesX = np.array([[1.5, 1], [2.4, 2], [3.5, 3]])y = np.array([2.1, 4.2, 5.9])learning_rate =0.01# Adding the learning_rate variable here, even though it's unused, for consistency.print("X =", X)print("y =", y)
X = [[1.5 1. ]
[2.4 2. ]
[3.5 3. ]]
y = [2.1 4.2 5.9]
La tasa de aprendizaje se estableció en 0.01. La tasa de aprendizaje es un hiperparámetro que afecta la velocidad y estabilidad del aprendizaje del modelo. Se inicializan los pesos y sesgos.
Code
m, n = X.shape# Initialize weights and biasweights = np.array([0.1, 0.1])bias =0.0# Corrected: Bias should be a single scalar value.print("X.shape =", X.shape)print("Initial weights =", weights)print("Initial bias =", bias)
El cálculo en dirección forward realiza una transformación lineal. La fórmula es la siguiente. \[ \boldsymbol y = \boldsymbol X \boldsymbol W + \boldsymbol b \]
He calculado hasta la pérdida. El siguiente paso es calcular el gradiente a partir de la pérdida. ¿Cómo se hace? Los gradientes de los pesos y sesgos son los siguientes.
\(\nabla_w = -\frac{2}{m}\mathbf{X}^T\mathbf{e}\)
\(\nabla_b = -\frac{2}{m}\mathbf{e}\)
Aquí, \(\mathbf{e}\) es el vector de error. Una vez que se han calculado los gradientes, se resta el valor del gradiente de los parámetros existentes para obtener el nuevo valor actualizado de los parámetros.
Code
weights_gradient =-2/m * np.dot(X.T, error)bias_gradient =-2/m * error.sum() # Corrected: Sum the errors for bias gradientweights -= learning_rate * weights_gradientbias -= learning_rate * bias_gradientprint("Updated weights =", weights)print("Updated bias =", bias)
El paso anterior es el cálculo backward (reverso). Se llama backpropagation (retropropagación) porque los gradientes se calculan y transmiten en orden inverso. Ahora implementamos todo el proceso de entrenamiento como una función.
Code
def train(X: np.ndarray, y: np.ndarray, lr: float, iters: int=100, verbose: bool=False) ->tuple:"""Linear regression training function. Args: X: Input data, shape (m, n) y: Target values, shape (m,) lr: Learning rate iters: Number of iterations verbose: Whether to print intermediate steps Returns: Tuple: Trained weights and bias """ m, n = X.shape weights = np.array([0.1, 0.1]) bias =0.0# Corrected: Bias should be a scalarfor i inrange(iters):# Forward pass y_predicted = np.dot(X, weights) + bias error = y - y_predicted# Backward pass weights_gradient =-2/m * np.dot(X.T, error) bias_gradient =-2/m * error weights -= lr * weights_gradient bias -= lr * bias_gradientif verbose:print(f"Iteration {i+1}:")print("Weights gradient =", weights_gradient)print("Bias gradient =", bias_gradient)print("Updated weights =", weights)print("Updated bias =", bias)return weights, bias
Prueba el modelo entrenado.
Code
# Train the modelweights, bias = train(X, y, learning_rate, iters=2000)print("Trained weights:", weights)print("Trained bias:", bias)# Test predictionstest_X = np.array([[1.5, 1], [2.4, 2], [3.5, 3]])test_y = np.dot(test_X, weights) + biasprint("Predictions:", test_y)
Se puede observar que en el caso de 50 iteraciones, hay un error bastante significativo entre los valores predichos y los reales. Otra cosa a considerar es la tasa de aprendizaje. ¿Por qué se multiplica un valor muy pequeño por el gradiente? Vamos a realizar una sola iteración e imprimir los valores de los parámetros calculados.
Code
num_iters =1weights, bias = train(X, y, learning_rate, iters=num_iters, verbose=True)
Al comparar los valores de los pesos y sesgos obtenidos después de 1000 iteraciones de entrenamiento, podemos ver que los valores del gradiente son muy grandes. Si no se reduce el valor del gradiente a un nivel muy bajo mediante la tasa de aprendizaje, los parámetros no podrán reducir el error y seguirán fluctuando. Se recomienda probar con una tasa de aprendizaje de un valor alto.
¿Cuál es la diferencia entre este ‘aproximador lineal’ y un aproximador de red neuronal? La diferencia es solo una: después del cálculo lineal, se pasa a través de una función de activación. Esto se expresa matemáticamente como:
\[ \boldsymbol y = f_{active} ( \boldsymbol x \boldsymbol W + \boldsymbol b ) \]
Implementar esto en código también es simple. Hay varias funciones de activación disponibles, y si usamos la función tanh, sería así.
Code
y_predicted = np.tanh(np.dot(X, weights) + bias)
Las redes neuronales expresan comúnmente cada paso de transformación lineal y aplicación de funciones de activación con el concepto de capa (layer). Por lo tanto, se prefiere implementarlos en dos pasos, ya que esta representación es más adecuada para las capas.
Code
out_1 = np.dot(X, weights) + bias # First layery_predicted = np.tanh(out_1) # Second layer (activation)
Haga clic para ver el contenido (deep dive: teoría de la plasticidad cortical)
Teoría de la plasticidad cortical (Cortical Plasticity Theory)
Teoría de la plasticidad cortical de Mountcastle
Vernon Mountcastle es un científico que realizó importantes contribuciones al campo de las neurociencias en la segunda mitad del siglo XX, especialmente conocido por sus investigaciones sobre la organización funcional de la corteza cerebral. Uno de los logros principales de Mountcastle fue el descubrimiento de la organización en columnas (Columnar Organization). Él demostró que la corteza cerebral está organizada en columnas verticales y que las neuronas dentro de la misma columna responden a estímulos similares.
La teoría de Mountcastle proporciona una base importante para comprender la plasticidad de la corteza cerebral. Según su teoría:
Columnas como unidades funcionales: La corteza cerebral está compuesta por columnas, que son las unidades funcionales básicas. Cada columna contiene un grupo de neuronas que responden a una modalidad sensorial específica o a un patrón de movimiento específico.
Plasticidad de las columnas: La estructura y función de las columnas pueden cambiar con la experiencia. La exposición repetida a ciertos estímulos puede aumentar el tamaño de las columnas que procesan esos estímulos o potenciar su reactividad. Por el contrario, la falta de estímulo puede reducir el tamaño de las columnas o disminuir su reactividad.
Interacción competitiva: Las columnas adyacentes interactúan entre sí de manera competitiva. Un aumento en la actividad de una columna puede inhibir la actividad de otras columnas, lo cual actúa como un mecanismo subyacente para la reorganización cortical según la experiencia. Por ejemplo, el uso frecuente de un dedo específico puede expandir la región cortical que controla ese dedo, mientras que las regiones que controlan otros dedos pueden reducirse en tamaño.
La teoría de Mountcastle sobre la estructura y plasticidad de las columnas tiene las siguientes implicaciones clínicas:
Recuperación después de lesiones cerebrales: La recuperación funcional después de un accidente cerebrovascular o una lesión cerebral traumática puede ocurrir mediante la reorganización de las regiones corticales adyacentes a las áreas dañadas.
Pérdida y rehabilitación sensorial: Después de la pérdida del sentido de la vista o el oído, las regiones corticales que procesaban esos sentidos pueden ser utilizadas para procesar otros sentidos (plasticidad cruzada modal, cross-modal plasticity).
Aprendizaje y adquisición de habilidades: Aprender nuevas habilidades o mejorar funciones específicas a través del entrenamiento repetitivo puede ajustar los pesos sinápticos en las redes neuronales, similar a cómo Mountcastle describió que la reactividad de las neuronas cambia con la experiencia.
Relación con el aprendizaje profundo
Estructura jerárquica: Los modelos de aprendizaje profundo tienen una estructura jerárquica similar a la organización en columnas de la corteza. Estos modelos constan de múltiples capas, y cada capa extrae características abstractas progresivamente más complejas de los datos de entrada. Esto es análogo a cómo las columnas corticales procesan información sensorial de manera incremental para realizar funciones cognitivas complejas.
Ajuste de pesos: Los modelos de aprendizaje profundo ajustan la intensidad de las conexiones (pesos) durante el proceso de entrenamiento para aprender la relación entre los datos de entrada y salida. Este mecanismo es similar al cambio en la intensidad de las conexiones neuronales dentro de una columna, como describió Mountcastle. Al igual que las neuronas pueden volverse más o menos reactivas a ciertos estímulos con la experiencia, los modelos de aprendizaje profundo ajustan sus pesos para mejorar el rendimiento.
Aprendizaje competitivo: Algunos modelos de aprendizaje profundo, especialmente los mapas autoorganizativos (Self-Organizing Map, SOM), utilizan principios similares a la interacción competitiva entre columnas. Los SOMs permiten que las neuronas compitan por el aprendizaje basado en las características de los datos de entrada, y solo el neurona ganadora se activa y actualiza los pesos de sus vecinos. Esto es similar a cómo las columnas adyacentes en la corteza cerebral pueden inhibirse mutuamente para dividir funciones competitivamente. La teoría de la plasticidad cortical del cerebro propuesta por Mountcastle no solo amplió nuestra comprensión de la organización funcional y los mecanismos de aprendizaje en el cerebro, sino que también proporcionó importantes insights para el desarrollo de modelos de deep learning. Los modelos de deep learning que imitan el funcionamiento del cerebro están contribuyendo significativamente al avance del campo de la inteligencia artificial, y se espera que la interacción entre la neurociencia y la inteligencia artificial sea aún más activa en el futuro.
1.5 Redes Neuronales Profundas
El aprendizaje profundo es un método que entrena redes neuronales con múltiples capas. Se utiliza el término ‘deep’ (profundo) debido a la profundidad de las capas. La capa lineal, componente básico, se conoce como capa completamente conectada (Fully Connected Layer) o capa densa (Dense Layer). Estas capas están estructuradas de la siguiente manera:
Capa completamente conectada 1 - Capa de activación 1 - Capa completamente conectada 2 - Capa de activación 2 - …
Las capas de activación desempeñan un papel crucial en las redes neuronales. Si solo se apilan capas lineales, matemáticamente resultaría en una única transformación lineal. Por ejemplo, dos capas lineales conectadas pueden expresarse como:
\[ \boldsymbol y = (\boldsymbol X \boldsymbol W_1 + \boldsymbol b_1)\boldsymbol W_2 + \boldsymbol b_2 = \boldsymbol X(\boldsymbol W_1\boldsymbol W_2) + (\boldsymbol b_1\boldsymbol W_2 + \boldsymbol b_2) = \boldsymbol X\boldsymbol W + \boldsymbol b \]
Esto resulta en otra transformación lineal. Por lo tanto, se pierde la ventaja de apilar múltiples capas. Las capas de activación rompen esta linealidad y permiten que cada capa aprenda de manera independiente. La razón del poder del aprendizaje profundo es precisamente que a medida que se apilan más capas, se pueden aprender patrones más complejos.
1.5.1 Estructura de las Redes Neuronales Profundas
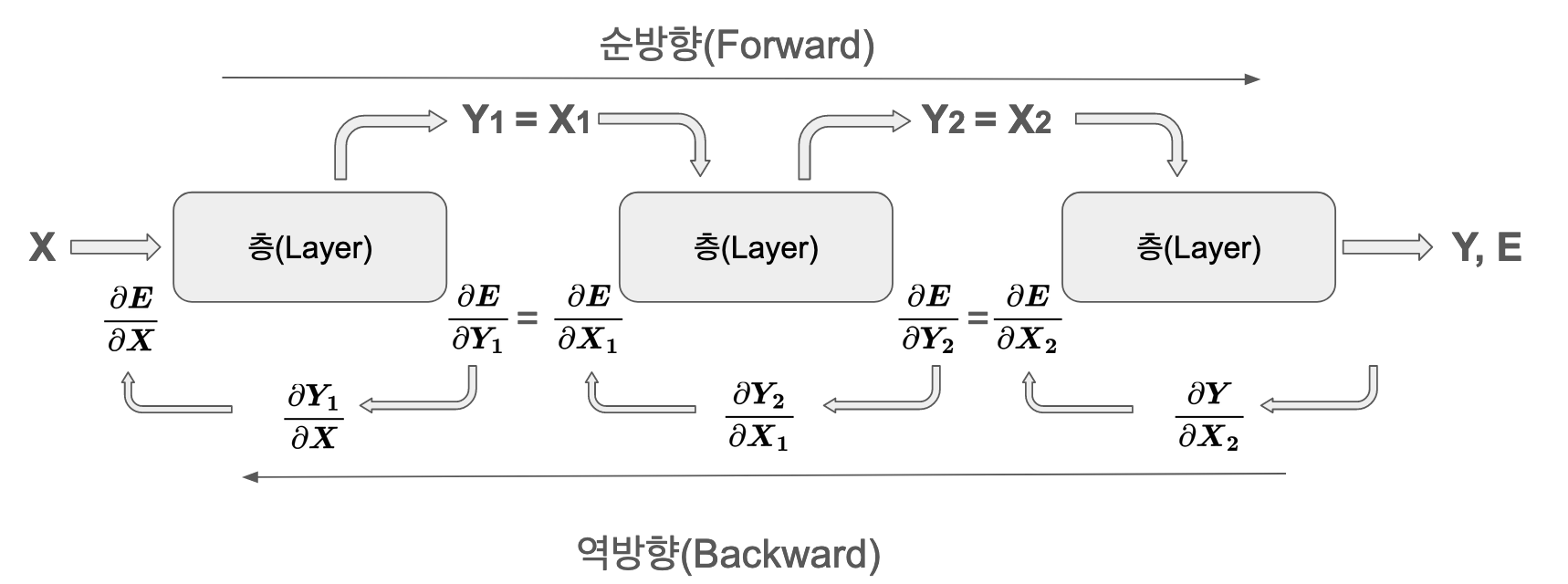
La salida de cada capa se convierte en la entrada de la siguiente capa, y los cálculos se realizan secuencialmente. La propagación hacia adelante es una serie de operaciones relativamente simples.
En la propagación hacia atrás, se calculan dos tipos de gradientes para cada capa:
Gradiente con respecto a los pesos: \(\frac{\partial E}{\partial \boldsymbol W}\) - utilizado para actualizar parámetros
Gradiente con respecto a las entradas: \(\frac{\partial E}{\partial \boldsymbol x}\) - propagado hacia la capa anterior
Estos dos gradientes deben ser almacenados y gestionados de manera independiente. El gradiente de los pesos se utiliza por el optimizador para actualizar los parámetros, mientras que el gradiente de las entradas se usa en el proceso de retropropagación para el aprendizaje de la capa anterior.
1.5.2 Implementación de Redes Neuronales
Para implementar la estructura básica de una red neuronal, aplicamos un diseño basado en capas. Primero definimos una clase base que todas las capas heredarán.
Code
import numpy as npclass BaseLayer():# __init__ can be omitted as it implicitly inherits from 'object' in Python 3def forward(self, x):raiseNotImplementedError# Should be implemented in derived classesdef backward(self, output_error, lr):raiseNotImplementedError# Should be implemented in derived classesdef print_params(self):# Default implementation (optional). Child classes should override.print("Layer parameters (Not implemented in BaseLayer)")# raise NotImplementedError # Or keep NotImplementedError
BaseLayer define la interfaz para las operaciones de propagación hacia adelante (forward) y hacia atrás (backward). Cada capa implementa esta interfaz para realizar sus propias operaciones únicas. A continuación se presenta la implementación de una capa completamente conectada.
Code
class FCLayer(BaseLayer):def__init__(self, in_size, out_size):# super().__init__() # No need to call super() for object inheritanceself.in_size = in_sizeself.out_size = out_size# He initialization (weights)self.weights = np.random.randn(in_size, out_size) * np.sqrt(2.0/ in_size)# Bias initialization (zeros)self.bias = np.zeros(out_size) # or np.zeros((out_size,))def forward(self, x):self.in_x = x # Store input for use in backward passreturn np.dot(x, self.weights) +self.biasdef backward(self, out_error, lr):# Matrix multiplication order: out_error (batch_size, out_size), self.weights (in_size, out_size) in_x_gradient = np.dot(out_error, self.weights.T) weight_gradient = np.dot(self.in_x.T, out_error) bias_gradient = np.sum(out_error, axis=0) # Sum over all samples (rows)self.weights -= lr * weight_gradientself.bias -= lr * bias_gradientreturn in_x_gradientdef print_params(self):print("Weights:\n", self.weights)print("Bias:\n", self.bias)
La capa completamente conectada transforma las entradas utilizando pesos y sesgos. Se aplicó la inicialización de pesos de He1. Este método fue propuesto por He et al. en 2015 y es especialmente efectivo cuando se utiliza junto con la función de activación ReLU.
Code
import numpy as npdef relu(x):return np.maximum(x, 0)def relu_deriv(x):return np.array(x >0, dtype=np.float32) # or dtype=intdef leaky_relu(x):return np.maximum(0.01* x, x)def leaky_relu_deriv(x): dx = np.ones_like(x) dx[x <0] =0.01return dxdef tanh(x):return np.tanh(x)def tanh_deriv(x):return1- np.tanh(x)**2def sigmoid(x):return1/ (1+ np.exp(-x))def sigmoid_deriv(x): # Numerically stable version s = sigmoid(x)return s * (1- s)
ReLU se convirtió en la función de activación estándar en el aprendizaje profundo desde su propuesta inicial en 2011. Tiene la ventaja de resolver eficazmente el problema del desvanecimiento del gradiente, mientras que también es simple de calcular. Para el cálculo inverso, declaramos la función derivada de la función de activación relu_deriv(). ReLU es una función que devuelve 0 si la entrada es menor que 0 y su propio valor si es mayor. Por lo tanto, la función derivada devuelve 0 para valores menores o iguales a 0 y 1 para valores mayores a 0. Aquí se utiliza Tanh como función de activación. A continuación se presenta la capa de activación.
La capa de activación añade no linealidad, permitiendo que la red neuronal pueda aproximar funciones complejas. Durante el proceso de retropropagación, se multiplica el gradiente con el error de salida según la regla de la cadena.
El error cuadrático medio (MSE) es una función de pérdida ampliamente utilizada en problemas de regresión. Calcula el promedio de las diferencias al cuadrado entre los valores predichos y los valores reales. Integrando estos componentes, se puede implementar la red neuronal completa.
Code
class Network:def__init__(self):self.layers = []self.loss =Noneself.loss_deriv =Nonedef add_layer(self, layer):self.layers.append(layer)def set_loss(self, loss, loss_deriv):self.loss = lossself.loss_deriv = loss_derivdef _forward_pass(self, x): output = xfor layer inself.layers: output = layer.forward(output)return outputdef predict(self, inputs): predictions = []for x in inputs: output =self._forward_pass(x) predictions.append(output)return predictionsdef train(self, x_train, y_train, epochs, lr):for epoch inrange(epochs): epoch_loss =0for x, y inzip(x_train, y_train):# Forward pass output =self._forward_pass(x)# Calculate loss epoch_loss +=self.loss(y, output)# Backward pass error =self.loss_deriv(y, output)for layer inreversed(self.layers): error = layer.backward(error, lr)# Calculate average loss for the epoch avg_loss = epoch_loss /len(x_train)if epoch == epochs -1:print(f'epoch {epoch+1}/{epochs} error={avg_loss:.6f}')
1.5.3 Entrenamiento de redes neuronales
El entrenamiento de una red neuronal es un proceso que implica la optimización de los pesos a través de la repetición de la propagación hacia adelante y la propagación hacia atrás. Primero, examinaremos el proceso de aprendizaje de las redes neuronales mediante el problema XOR.
La función de activación se entrenó usando tanh(). Se puede verificar que la red neuronal ha sido entrenada para producir valores similares para la lógica de salida XOR. Ahora examinaremos el aprendizaje de redes neuronales con un conjunto de datos real a través del problema de clasificación de dígitos manuscritos MNIST.
El siguiente es un ejemplo de escritura a mano de MNIST. Primero, importamos las bibliotecas necesarias para usar PyTorch.
Code
import torchimport torchvisionimport torch.nn.functional as Ffrom torchvision.datasets import MNISTimport matplotlib.pyplot as pltimport torchvision.transforms as transformsfrom torch.utils.data import random_splitdataset = MNIST(root ='data/', download =True)print(len(dataset))
Las etiquetas de escritura a mano no son de tipo entero, no están en formato categórico. Crearemos y usaremos una función similar a to_categorical en keras.
Code
def to_categorical(y, num_classes):""" 1-hot encodes a tensor """return np.eye(num_classes, dtype='uint8')[y]
Después de cargar los datos, los dividí en dos conjuntos: uno para entrenamiento y otro para prueba. Usé DataLoader de PyTorch para cargar los datos. Aquí, para usar solo 2000 muestras de datos de entrenamiento, establecí el batch_size en 2000. Luego, con next(iter(train_loader)), obtuve solo un lote una vez y cambié la forma de los datos de (1, 28, 28) a (1, 784). Esto se llama aplanamiento. Después de procesar por separado los datos de imagen y etiqueta, verifiqué las dimensiones.
/tmp/ipykernel_936812/3322560381.py:14: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
return np.dot(x, self.weights) + self.bias
/tmp/ipykernel_936812/3322560381.py:19: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
weight_gradient = np.dot(self.in_x.T, out_error)
epoch 35/35 error=0.002069
Code
# Make predictions with the trained model.test_images, test_labels =next(iter(test_loader))x_test = test_images.reshape(test_images.shape[0], 1, 28*28)y_test = to_categorical(test_labels, 10)print(len(x_test))# Use only the first 2 samples for prediction.out = net.predict(x_test[:2]) # Corrected slicing: use [:2] for the first two samplesprint("\n")print("Predicted values : ")print(out, end="\n")print("True values : ")print(y_test[:2]) # Corrected slicing: use [:2] to match the prediction
/tmp/ipykernel_936812/3322560381.py:14: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
return np.dot(x, self.weights) + self.bias
Hasta ahora, hemos implementado directamente la forma más básica de red neuronal, es decir, un “aproximador de funciones (function approximator)” que realiza predicciones apilando capa tras capa transformaciones lineales y funciones de activación no lineales. Desde el problema simple XOR hasta la clasificación de dígitos manuscritos MNIST, hemos examinado los principios fundamentales de cómo las redes neuronales aprenden a través de datos y reconocen patrones complejos. Los marcos de deep learning como PyTorch y TensorFlow hacen este proceso mucho más eficiente y conveniente, pero el funcionamiento fundamental no difiere significativamente del código que implementamos directamente.
Este libro continuará rastreando la evolución de las tecnologías de deep learning desde la neurona McCulloch-Pitts en 1943 hasta las arquitecturas multimodales más recientes en 2025. Examinaremos profundamente por qué surgieron cada una de estas tecnologías, cuáles problemas fundamentales intentaron resolver y cómo están conectadas con las tecnologías anteriores, al igual que si estuviéramos investigando la evolución de un organismo.
En el Capítulo 2, abordaremos los fundamentos matemáticos esenciales para comprender el deep learning. Resumiremos concisamente los conceptos clave del álgebra lineal, cálculo, probabilidad y estadística desde la perspectiva del deep learning, con el fin de facilitar la comprensión de los contenidos posteriores. Si te falta conocimiento de matemáticas o estás más interesado en la implementación práctica que en la teoría, puedes saltar directamente al Capítulo 3. A partir del Capítulo 3, podrás implementar y experimentar con los modelos de deep learning más recientes utilizando PyTorch y las bibliotecas Hugging Face, adquiriendo un sentido práctico del trabajo real. Sin embargo, para una comprensión profunda y el desarrollo a largo plazo en deep learning, es muy importante sentar bases matemáticas sólidas.
Al final de cada capítulo, proporcionaremos problemas de ejercicios para que puedas evaluar tu comprensión y obtener un punto de partida para investigaciones adicionales. Esperamos que vayas más allá de simplemente encontrar las respuestas y profundices en los principios del deep learning durante el proceso de resolución de problemas, expandiendo así tu pensamiento creativo.
Ejercicios de práctica
1. Problemas básicos
Explique matemáticamente por qué un perceptrón no puede resolver el problema XOR.
Explique los resultados si se cambian las funciones de activación a relu, relu_deriv en el ejemplo XOR anterior.
Explique con un ejemplo cómo se aplica la regla de la cadena en el algoritmo de retropropagación.
2. Problemas aplicados
Análisis de las ventajas y desventajas de usar la función de activación Swish en lugar de ReLU en modelos de predicción de precios de viviendas.
Explique por qué la capacidad expresiva de una red neuronal con tres capas es superior a la de una red con dos capas desde la perspectiva del espacio de funciones.
3. Problemas avanzados
Pruebe matemáticamente el mecanismo por el cual las conexiones de salto en ResNet resuelven el problema de desvanecimiento del gradiente.
Analice por qué el mecanismo de atención en la arquitectura Transformer es adecuado para modelar secuencias.
Haga clic para ver el contenido (solución)
Solución
1. Respuestas a problemas básicos
Problema XOR: Limitación de los clasificadores lineales → Necesidad de una frontera de decisión no lineal
import numpy as npXOR_input = np.array([[0,0],[0,1],[1,0],[1,1]])# Con combinaciones lineales no es posible distinguir entre 0 y 1
Problema de entrenamiento con ReLU: ReLU: Es sensible a la tasa de aprendizaje y tiene una alta probabilidad de presentar el problema de “Dead ReLU” (neuronas inactivas que no pueden aprender). Otros funciones de activación (Leaky ReLU, ELU, Swish) pueden mitigar el problema de Dead ReLU y son más estables para resolver el problema XOR. Sigmoid puede tener dificultades para aprender debido al problema de desvanecimiento del gradiente. Tanh es más estable que ReLU, pero en redes profundas también puede sufrir del problema de desvanecimiento del gradiente.
Regla de la cadena en retropropagación: \(\frac{\partial L}{\partial W} = \frac{\partial L}{\partial y}\cdot\frac{\partial y}{\partial W}\)
2. Respuestas a problemas aplicados
Ventajas de la función Swish:
Mitiga el problema de neuronas inactivas en ReLU
Curva diferenciable que mejora la estabilidad del aprendizaje
Superioridad de las redes neuronales de 3 capas:
Problema 13 de Hilbert: Las funciones continuas de 3 variables no pueden ser representadas por una red de 2 capas
Teorema de Kolmogorov–Arnold: Es posible aproximar cualquier función continua con una red de 3 capas